

La ejecución de cada instrucción de lenguaje de máquina conlleva casi siempre varias tareas menores:
1] Traer la instrucción de la memoria. A esto en la jerga de los arquitectos de computadoras se le denomina fetch, por la palabra en inglés equivalente a traer.
2] Determinar los operandos y disponerlos como entrada a la unidad aritmético-lógica. Esta etapa recibe el nombre de decodificación.
3] Ejecutar la operación. Lo que suele llamarse ejecución propiamente dicha.
4] Alterar el estado del procesador de acuerdo con el resultado obtenido, en particular escribirlo en alguno de los registros. A lo que, nuevamente en la jerga de los arquitectos, se le denomina write-back y que en esencia significa escribir resultados.
A partir del decenio de los ochenta del siglo pasado, los diseñadores de procesadores se dieron cuenta de que, si lograban hacer que todas las etapas de todas las instrucciones tardaran el mismo tiempo, podían lograr que la ejecución de programas en el procesador fuera mucho más eficiente. El truco es usar la misma estrategia que usó Henry Ford para producir en serie el famoso Modelo T, el primer automóvil hecho en una línea de ensamblaje. Ford dividió el proceso de elaboración de un Modelo T en varias etapas; normalmente todas las etapas serían ejecutadas por un equipo de obreros sobre un automóvil, una tras otra hasta terminarlo y sólo entonces podrían comenzar con uno nuevo. En este esquema, si cada etapa tarda, digamos, 12 minutos, y hay un total de cinco etapas, entonces cada automóvil tardará una hora en ser armado; un observador colocado fuera de la planta de producción vería entonces salir un automóvil por hora.
Ahora cámbiese el esquema, en vez de que todos los obreros estén haciéndose bolas sobre un solo coche a la vez, hay que ponerlos a lo largo de una línea junto a una banda móvil. Sobre la banda se coloca un chasis y se mueve hasta el primer obrero que se encarga solamente de llevar a cabo las tareas de la primera etapa, luego de 12 minutos se le pone un nuevo chasis en la banda y se desplaza un lugar hacia adelante. Ahora, el primer obrero recibe un nuevo chasis sobre el que trabaja y el segundo obrero de la fila puede hacer las labores propias de la segunda etapa sobre el automóvil que acaba de ser trabajado por el primer obrero. Luego de 12 minutos, se repite la operación hasta que al cabo de una hora ya todos los obreros están trabajando: cada uno haciendo sólo una de las etapas y nada más, cada uno sobre un automóvil diferente, pero todos al mismo tiempo. Por supuesto, el tiempo de elaboración de cada automóvil no cambia, sigue siendo de una hora, pero ahora el observador externo ve salir un automóvil completo cada 12 minutos y no cada hora como antes.
Cada una de las etapas listadas arriba para la ejecución de una instrucción tarda una unidad de tiempo pequeña (en las computadoras actuales es realmente pequeña, posiblemente una fracción de nanosegundo) y, por cierto, es justo el tamaño de esa unidad lo que determina la duración de los mencionados ciclos de reloj. Si todas tardan lo mismo se podría pensar en hacer lo análogo a una línea de ensamble: un trozo del procesador trae la nésima instrucción del programa, al mismo tiempo otro trozo del procesador hace la decodificación de la instrucción inmediata anterior, la n – 1; al mismo tiempo, otro trozo del procesador ejecuta en la ALU la operación de la instrucción n – 2; simultáneamente, otro fragmento más realiza la escritura de resultados de la instrucción n – 3. ¡Brillante! ¿No?
A esta estrategia se le denomina ejecución de cauce segmentado. Suena complicado. El término en inglés es pipeline, que literalmente significa tubería, pero no dice mucho, así que es mejor usar el complicado término en español en vez de la traducción literal.
Curiosidades
En 1780, un estadunidense de nombre Oliver Evans dividió el proceso de elaboración de harina de trigo en etapas y luego hizo que cada uno de los empleados del molino se dedicara a una y sólo una de las etapas de producción de harina. Éste es el primer ejemplo de lo que se conoce como línea de producción. Más tarde, en 1913, Henry Ford implantó un sistema similar para producir en serie su famoso Modelo T. En la línea de ensamble de Ford había estaciones, en cada una de las cuales se llevaba a cabo una labor particular: en una se colocaba el motor, en otra las puertas, en otra el radiador, etc. Por un lado de la línea entraba sólo el chasis de los automóviles, y a lo largo de ella se iba completando paulatinamente hasta que al final de la línea salía completo. Éste es precisamente el principio del concepto de cauce segmentado o pipeline en inglés.
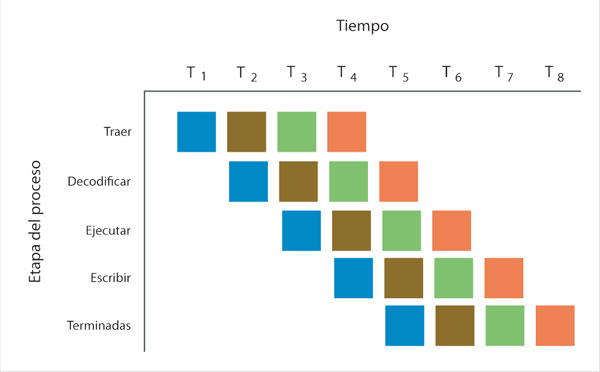
En la figura 15, cada instrucción se representa con un color diferente. A partir de T1, en cada paso temporal (ciclo de reloj) se alimenta una nueva instrucción al procesador. A partir de T5, se termina con una instrucción en cada paso temporal.
La ejecución de cauce segmentado parece más fácil de lo que es en realidad, pues hay algunos problemas no triviales que resolver para implementarla. Por ejemplo: ¿qué pasa si la instrucción n – 1, en su fase de decodificación, necesita un dato almacenado en un registro que aún no ha sido escrito en él por la instrucción n – 3? Esto es perfectamente plausible, porque después de todo la instrucción n – 3 precede a la n – 1, y ésta puede basar su operación en los datos calculados por aquélla. A un problema como éste se le denomina conflicto de datos (en inglés data hazard) y su solución eficiente excede con mucho el alcance de este libro. La solución fácil es detener toda la "línea de producción" salvo aquellas etapas que están calculando lo que se necesita para continuar; esto introduce intervalos de espera indeseables en los que el procesador no está ocupado al cien por ciento.
Los procesadores actuales llevan el concepto de cauce segmentado aún más allá. Actualmente poseen no sólo una, sino varias "líneas de ensamble", varios cauces dedicados a tareas específicas: uno para operaciones aritmético-lógicas con números enteros, otro para instrucciones de acceso a memoria y otro para operaciones que tienen que ver con el manejo de gráficos en la pantalla, por ejemplo. Así, cada instrucción se coloca en el cauce que le corresponde una vez que se determina de qué tipo es. A esto se le denomina ejecución superescalar. Prácticamente todos los procesadores de este siglo son superescalares.
Curiosidades
El hecho mencionado, de que ya es prácticamente imposible continuar con un crecimiento de densidad como el establecido por la ley de Moore, traería como consecuencia un estancamiento en la velocidad de los procesadores. Para paliar, no resolver, el problema, desde hace unos años se diseñan arquitecturas de procesadores en los que realmente hay más de una unidad de procesamiento en cada chip. A esto se le ha llamado arquitectura multinúcleo (multicore en inglés). El desempeño de una de estas arquitecturas no es comparable al que se obtendría incrementando la densidad al ritmo señalado por la ley de Moore, pero al menos permite no dejarlo igual. En una arquitectura multinúcleo, cada núcleo se encarga de su propia secuencia de instrucciones, se podría decir, sin ser del todo precisos, que se encarga de su propio subprograma, a lo que se le suele llamar hilo de ejecución. Por lo que realmente es una pequeña computadora en la que se ejecutan en paralelo (simultáneamente) varios hilos de ejecución.